When in the Course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the Laws of Nature and of Nature’s God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation.
Services have to be independent. They can achieve Independent Scalability and Independent Lifecycle by having Independent Data, Independent Code and Independent Deployments.
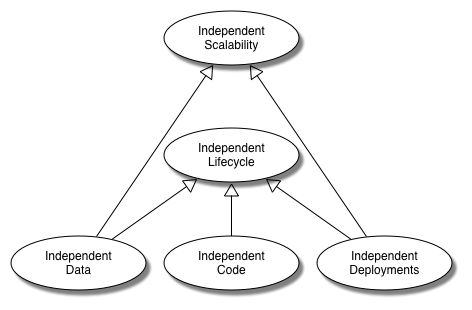
Independent Scalability
The only way to scale monolithic system is to scale it horizontally. Splitting to independent components allows to scale each component individually. This not only saves your resources, but, most importantly, does not allow parts of the system to starve other parts. You may need to think about independent scalability when you have independent operations (APIs) with:
- different resource needs (e.g. CPU- vs. memory-bound).
- different SLAs (fast vs. slow).
- different load (request rate)
- different reliability requirements
- different clients (e.g. end users vs. API clients)
Independent Lifecycle
When you have parts of your system evolving at a different pace, you do not want to tie together their delivery cycles.
Independent lifecycle of services gives us an ability to update any service without impacting the whole system, as long as the change is backwards-compatible. And, with well designed services, we are getting also encapsulation of the risk — failing service should fail only some of system functionality, failing component inside a monolith will crash everything.
Independent Data
We should never depend on internals of data managed by the services. It is their “implementation details”. Service should be always free to change underlying data format and/or storage. Services accessing the same data directly (or even having an easy way to do so) either are already too tightly coupled, or will be tomorrow.
There are only two ways to achieve data independence: to have well-defined bounded context for a service, managed in the independent data store; or to have no data at all (stateless services).
Independent Code
Services should never have code dependencies on each other. Code for each service is its implementation detail, and should be completely hidden from any other service. They can depend on common libraries, but only if these libraries have much higher stability than services themselves. Strictly speaking, one can achieve independent scalability even with code dependencies, but independent lifecycle is impossible if code of one service depends on another’s.
Independent Deployments
Services have to be deployable independently. As soon as you are in a situation where you need simultaneous/orchestrated deployment of multiple services, you are doing something wrong.
Applying Independence Test
With all these independence clauses we can create a rule for when, why and how to make your services independent:
- You should look at splitting your monoliths to services when and if you need (and I mean it, need, not want) Independent Scalability and Independent Lifecycle
- To do this, you have to make your Data, Code and Deployments Independent
This is an updated version of declaration that hat its first appearence in the Can I Haz Name? post